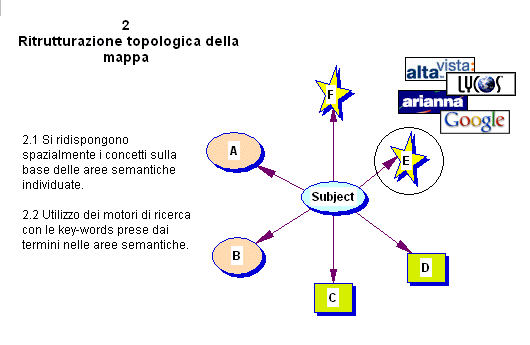
2. Ri-strutturazione topologica della mappa sulla base
delle aree semantiche indivi-duate e uso dei motori di ricerca
con le parole chiave di ciascuna area.
Nella fase 2, i concetti che vengono ritenuti fortemente
correlati sono raggruppati assieme e viene loro attribuito
un "box" (quadrato, cerchio, rettangolo, ecc..)
ed un colore specifici. Questo approccio da un lato si rifà
direttamente alla teoria della Gestalt per quanto riguarda
il raggruppamento (grouping) (Moore, Fitz 1993) di stimoli
visivi secondo i fattori di:
• Prossimità (oggetti vicini tra loro
sono percepiti come un gruppo )
• Similarità (oggetti dalla forma simile
sono percepiti come un gruppo)
e dall'altro sulle numerose ricerche di psicologia cognitiva
sul semantic priming (Rhodes, 1993) (Plaut, 2000) e sull'
effetto contesto (Lavigne, 2000) secondo le quali viene
favorita la percezione e il riconoscimento di parole contigue
appartenenti ad un contesto semanticamente omogeneo (es.
forchetta-coltello-cucchiaio).
Vi sono inoltre forti prove sperimentali (Meara, 1978) per
cui parole semanticamente correlate sembra siano collocate
in modo contiguo nello spazio del nostro lessico mentale,
per cui la visione di un certo termine tende a far affiorare
alla mente tutto un insieme di altre parole strettamente
correlate ad esso.
Nel corso degli anni sono stati sviluppati molti metodi
per rappresentare il potenziale semantico/associativo delle
parole, il primo è stato il differenziale semantico
di Osgood in cui il test, nella sua versione originale,
è costituito da un insieme di scale di aggettivi
bipolari graduate in intensità per esprimere il proprio
giudizio rispetto ad un concetto dato. Il significato specifico
che tale concetto ha per il soggetto viene identificato
quantitativamente come un punto preciso nello spazio semantico
multidimen-sionale. La parola "dittatore" ad esempio
può essere giudicata in più scale: buono/cattivo,
altruisti-co/egoistico o caldo/freddo, ecc. Il punteggio
medio ottenuto sulle varie scale definisce le coordinate
della parola nello spazio semantico. Parole semanticamente
vicine probabilmente otterranno punteggi simili e verranno
collocate spazialmente vicine. Il problema di questo approccio
è la sua arbitrarietà nello scegliere il tipo
di scale e il loro numero.
Recentemente è stato messo a punto un metodo statistico,
il Latent Semantic Analysis (LSA), per costruire spazi semantici
che non dipendono dal giudizio interattivo del soggetto,
ma da una analisi automatica del testo. (Landauer &
Dumais, 1997). L’assunto della LSA è che parole
simili occorrono in contesti simili. Ad esempio in una parte
di testo dove si parla di “gatti” è probabile
che questo menzioni anche “topi” o “cani”.
Questa conoscenza sulla prossimità delle parole può
essere usata per assumere che “gatti” e “topi”
sono in qualche modo correlati semanticamente. Il risultato
dell’analisi è uno spazio multidimensionale
in cui parole che appaiono in contesti simili sono collocate
in aree spaziali contigue.